
The Natural Language ToolKit (NLTK) is the most popular library for natural language processing (NLP) in Python. The authors also created the NLTK textbook, which is a great resource for learning how to use NLTK. This notebook is a compilation of the parts of NLTK that I found most interesting.
Chapter 1
import nltk
#First, let's grab some text to work with
from nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
#Let's see how Melville uses the word "literally"
text1.concordance('literally')
Displaying 5 of 5 matches:
ich the first syllable of the word literally expresses . In those times , also
n officer called the Specksynder . Literally this word means Fat - Cutter ; usa
acing everything out to the last , literally died at his post . Of modern stand
he White Whale ; a name , indeed , literally justified by his vivid aspect , wh
d up that uncontaminated aroma ,-- literally and truly , like the smell of spri
#Let's see how long people lived in the Bible
text3.concordance('lived')
Displaying 25 of 38 matches:
ay when they were created . And Adam lived an hundred and thirty years , and be
ughters : And all the days that Adam lived were nine hundred and thirty yea and
nd thirty yea and he died . And Seth lived an hundred and five years , and bega
ve years , and begat Enos : And Seth lived after he begat Enos eight hundred an
welve years : and he died . And Enos lived ninety years , and begat Cainan : An
years , and begat Cainan : And Enos lived after he begat Cainan eight hundred
ive years : and he died . And Cainan lived seventy years and begat Mahalaleel :
rs and begat Mahalaleel : And Cainan lived after he begat Mahalaleel eight hund
years : and he died . And Mahalaleel lived sixty and five years , and begat Jar
s , and begat Jared : And Mahalaleel lived after he begat Jared eight hundred a
and five yea and he died . And Jared lived an hundred sixty and two years , and
o years , and he begat Eno And Jared lived after he begat Enoch eight hundred y
and two yea and he died . And Enoch lived sixty and five years , and begat Met
; for God took him . And Methuselah lived an hundred eighty and seven years ,
, and begat Lamech . And Methuselah lived after he begat Lamech seven hundred
nd nine yea and he died . And Lamech lived an hundred eighty and two years , an
ch the LORD hath cursed . And Lamech lived after he begat Noah five hundred nin
naan shall be his servant . And Noah lived after the flood three hundred and fi
xad two years after the flo And Shem lived after he begat Arphaxad five hundred
at sons and daughters . And Arphaxad lived five and thirty years , and begat Sa
ars , and begat Salah : And Arphaxad lived after he begat Salah four hundred an
begat sons and daughters . And Salah lived thirty years , and begat Eber : And
y years , and begat Eber : And Salah lived after he begat Eber four hundred and
begat sons and daughters . And Eber lived four and thirty years , and begat Pe
y years , and begat Peleg : And Eber lived after he begat Peleg four hundred an
#What other words are used in place of 'lived'
text3.similar('lived')
went took dwelt builded
#You used the word 'affectionate', but we're not sure it's used in the best way possible. Here are some examples of how Jane Austen used it
text2.concordance('affectionate')
Displaying 22 of 22 matches:
nt heart ;-- her disposition was affectionate , and her feelings were strong ;
ve every indication of an open , affectionate heart . His understanding was go
heart to be warm and his temper affectionate . No sooner did she perceive any
u will gain a brother , a real , affectionate brother . I have the highest opi
een wholly engrossed on the most affectionate principle by my mother . I have
e : it was the good wishes of an affectionate brother to both . Twice did I le
on , lively spirits , and open , affectionate manners . He was exactly formed
he rest of the family it was the affectionate attention of a son and a brother
h us so happy , so cheerful , so affectionate ? And now , after only ten minut
, his manner , his attentive and affectionate respect ? My Elinor , is it poss
, and perceiving through all her affectionate attention to herself , how much
h the same steady conviction and affectionate counsel on Elinor ' s side , the
nly what was amiable in it , the affectionate heart which could not bear to se
and urged by a strong impulse of affectionate sensibility , she moved after a
heart ,' says poor Fanny in her affectionate way , ' that we had asked your s
Mrs . Ferrars is one of the most affectionate mothers in the world ." Elinor w
nguish every thing that was most affectionate and graceful . CHAPTER 42 One ot
hort note from Marianne -- still affectionate , open , artless , confiding --
pen and honest , and a feeling , affectionate temper . The world had made him
ncommon attraction , that open , affectionate , and lively manner which it was
h no remarks , no inquiries , no affectionate address of Mrs . Dashwood could
neither less frequent , nor less affectionate than usual . Not the smallest su
text5.concordance('hello')
Displaying 25 of 92 matches:
s in the corner - . JOIN phone U92 ? hello U84 . ACTION sits with U92 . hmph .
U68 . does that mean I want you ? U6 hello room lol U83 and this .. has been th
, i dont do shit , im the supervisor Hello U165 . hey U165 how 's u ? . ACTION
pissed at you i 'm sure ... lol :-) hello ... oopps I meant martini's lmao U17
wo n't psh anymore buttons .... lol hello everyone yes .... hey U29 oh you mea
! JOIN hey U31 ... welcome cool U31 hello U9 :) hey U31 U11 *hugs* are you sex
ore ... hi U36 I 'm an over achiever hello whjat nationality are you U35 ? hell
ello whjat nationality are you U35 ? hello U36 who 's horny ? Is U17 writing a
n't play a dumbass be gente .... lol hello . ACTION hi . hi all LOL my pic woul
soul . :blush: hi U12 lol U28 U42 : Hello there . i despie no one i like to sa
T No luck hi U17 is the sky purple ? hello U17 Hi , U44 hey U42 it black here b
u need a sugar subsitute JOIN wb U27 hello all this comp is freaing me out lol
11 U33 JOIN hi U26 hi U34 hi U16 U34 hello U34 hi U9 true ... lol i just did Hi
N hi U43 hi U19 and ty hi U30 hi U34 hello all hi U44 nebraska is where its at
uskers hi U44 lol U9 and JOIN hi U35 hello U44 corn hi U45 and well i off now s
he roof the roof the roof is on fire Hello U44 .. :) and U3 ! :) hi U54 congrat
oh wait ........ thats a Whistlin ;) Hello U9 thank god you were singing ! was
wamp music ... hey U55 , good to c u Hello U11 lol U3 be nice U3 lol Hey there
29 U13 .... im down to time now PART Hello U24 , welcome to #talkcity_adults !
the " pussy pink " JOIN lol lmao U23 hello all pussy pink Really ? Wow . . I to
om hon can i get an amen for myspace Hello lovelies a alo U36 . ACTION peeks in
eesh were attracted or ARE attracted Hello ca n't even get kicked . ACTION is h
me to =) lol U35 tell it like it is hello reallly brrrrrrr LOL U35 wanna bet h
!. hi Oh my U15 . . LoL too late U15 hello U53 agaibn ? . ACTION listenin to Ev
sst U16 open your eyes and you might hello U20 PART alzheimers ? U34 ... how is
#What other words are used in a similar context as 'smart'?
text5.similar('hello')
hi part lol join hey and hiya right all m there what one too where wb
hugs if nite cool
#Let's see where in the text Jane Austen uses 'affectionate' versus 'angry'
text2.dispersion_plot(['affectionate', 'angry'])

#We can also generate random text in the style of Jane Austen
#text2.generate() #This function has been temporarily disabled in nltk 3
#Let's see how many different words she uses in her book.
#Note that this will also count punctuation
sorted(set(text2))[1000:1050] # skipping ahead of the punctuation
['amply',
'amuse',
'amused',
'amusement',
'amusements',
'amusing',
'an',
'ancient',
'and',
'anew',
'angel',
'anger',
'angrily',
'angry',
'anguish',
'animated',
'animating',
'animation',
'ankle',
'ankles',
'annexed',
'annihilation',
'announce',
'announced',
'announcing',
'annuities',
'annuity',
'annum',
'another',
'answer',
'answerable',
'answered',
'answering',
'answers',
'anticipate',
'anticipated',
'anticipating',
'anticipation',
'anticipations',
'anxiety',
'anxious',
'anxiously',
'any',
'anybody',
'anymore',
'anything',
'apartment',
'apartments',
'apiece',
'apologies']
#Now let's count the words
print(len(set(text2)))
#We can also count the amount of times a single word appears
print(text2.count('happy'))
6833
96
#We can also find the most common words in this text:
fdist = FreqDist(text2)
If you try to return fdist you get the words in the order they first appear, which often isn’t particularly useful. The best way is to use a method, such as most_common
fdist.most_common(10)
[(',', 9397),
('to', 4063),
('.', 3975),
('the', 3861),
('of', 3565),
('and', 3350),
('her', 2436),
('a', 2043),
('I', 2004),
('in', 1904)]
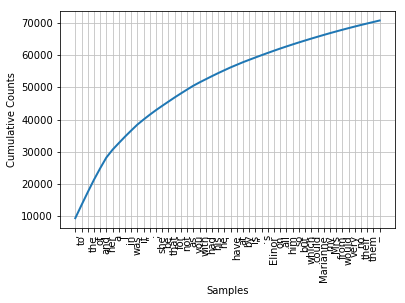
#How much of the book is the most common fifty words? Here's what it looks like for Jane Austen:
fdist.plot(50, cumulative=True)
#Maybe you could try to reduce some of your use?
#What words occur only once? These are called hapaxes, and we'll take a look at them:
fdist.hapaxes()[:50]
['Sense',
'Sensibility',
'Jane',
'Austen',
'1811',
']',
'generations',
'inheritor',
'bequeath',
'Gentleman',
'relish',
'devolved',
'inheriting',
'moiety',
'bequest',
'sale',
'articulation',
'economically',
'tardy',
'survived',
'including',
'legacies',
'urgency',
'prudently',
'caricature',
'warmed',
'Three',
'successively',
'funeral',
'dispute',
'decease',
'indelicacy',
'keen',
'whomsoever',
'immoveable',
'acutely',
'qualified',
'counsellor',
'joys',
'afflicted',
'strive',
'humored',
'imbibed',
'romance',
'thirteen',
'2',
'installed',
'degraded',
'seasons',
'alloy']
#Now let's find all the long words in her book:
V = set(text2)
long_words = [w for w in V if len(w) > 15]
sorted(long_words)
#Looks like she didn't use very many long words
['companionableness',
'disinterestedness',
'disqualifications',
'incomprehensible']
#Maybe the best way to get an idea of the focus of a text is to look for all the long words that are used repeatedly
#Another way to do this would be to look for infrequent words
sorted(w for w in set(text2) if len(w) > 7 and fdist[w] > 7)[:50]
['Allenham',
'Berkeley',
'Certainly',
'Charlotte',
'Cleveland',
'Dashwood',
'Dashwoods',
'Delaford',
'Devonshire',
'Jennings',
'Longstaple',
'Margaret',
'Marianne',
'Middleton',
'Middletons',
'Somersetshire',
'Whatever',
'Willoughby',
'abilities',
'absolutely',
'acknowledge',
'acknowledged',
'acquaintance',
'acquainted',
'admiration',
'advanced',
'advantage',
'affected',
'affection',
'affectionate',
'affections',
'affliction',
'afterwards',
'agitation',
'agreeable',
'alteration',
'altogether',
'amazement',
'amusement',
'answered',
'anything',
'appearance',
'appeared',
'approbation',
'arranged',
'assertion',
'assistance',
'assurance',
'assurances',
'astonished']
#We can also find words that appear in sets of two. These are known as bigrams
import nltk
print(list(nltk.bigrams(['more', 'is', 'said', 'than', 'done'])))
text2.collocations()
#Collocations can be a good way to discern meaning from text
[('more', 'is'), ('is', 'said'), ('said', 'than'), ('than', 'done')]
Colonel Brandon; Sir John; Lady Middleton; Miss Dashwood; every thing;
thousand pounds; dare say; Miss Steeles; said Elinor; Miss Steele;
every body; John Dashwood; great deal; Harley Street; Berkeley Street;
Miss Dashwoods; young man; Combe Magna; every day; next morning
#Now let's see what the distribution of word length is:
[len(w) for w in text2]
fdist = FreqDist(len(w) for w in text2)
fdist
FreqDist({1: 23009,
2: 24826,
3: 28839,
4: 21352,
5: 11438,
6: 9507,
7: 8158,
8: 5676,
9: 3736,
10: 2596,
11: 1278,
12: 711,
13: 334,
14: 87,
15: 24,
16: 2,
17: 3})
#Or you could sort them by most common:
fdist.most_common()
[(3, 28839),
(2, 24826),
(1, 23009),
(4, 21352),
(5, 11438),
(6, 9507),
(7, 8158),
(8, 5676),
(9, 3736),
(10, 2596),
(11, 1278),
(12, 711),
(13, 334),
(14, 87),
(15, 24),
(17, 3),
(16, 2)]
#Now let's count our vocab but remove punctuation and capitalization first
len(set(word.lower() for word in text2 if word.isalpha()))
6283
Chapter 2
#Now let's look at a different text - Emma, by Jane Austen
nltk.corpus.gutenberg.fileids()
emma = nltk.corpus.gutenberg.words('austen-emma.txt')
len(emma)
192427
#Let's do some quick analysis on all the books listed. We want to learn the average word length, number of words per sentence,
#and the number of unique words divided by the total number of words
from nltk.corpus import gutenberg
for fileid in gutenberg.fileids():
num_chars = len(gutenberg.raw(fileid)) #This counts spaces, so it should be one less than that
num_words = len(gutenberg.words(fileid))
num_sents = len(gutenberg.sents(fileid))
num_vocab = len(set(w.lower() for w in gutenberg.words(fileid)))
print(round(num_chars/num_words), round(num_words/num_sents), round(num_words/num_vocab), fileid)
5 25 26 austen-emma.txt
5 26 17 austen-persuasion.txt
5 28 22 austen-sense.txt
4 34 79 bible-kjv.txt
5 19 5 blake-poems.txt
4 19 14 bryant-stories.txt
4 18 12 burgess-busterbrown.txt
4 20 13 carroll-alice.txt
5 20 12 chesterton-ball.txt
5 23 11 chesterton-brown.txt
5 18 11 chesterton-thursday.txt
4 21 25 edgeworth-parents.txt
5 26 15 melville-moby_dick.txt
5 52 11 milton-paradise.txt
4 12 9 shakespeare-caesar.txt
4 12 8 shakespeare-hamlet.txt
4 12 7 shakespeare-macbeth.txt
5 36 12 whitman-leaves.txt
#We can also do a deep dive on humor by using the Brown corpus
from nltk.corpus import brown
#Let's make a function to see how a particular genre uses a group of words
def genre_word_usage(genre, words):
'''
This function accepts a genre as specified by the Brown corpus and any list of words, and shows how that genre uses
that list of words. The result will be printed.
'''
genre_text = brown.words(categories=[genre])
fdist = nltk.FreqDist(w.lower() for w in genre_text)
for word in words:
print(word + ':', fdist[word], end=' ')
#Now let's see how humor and news use the "w words" differently
w_words = ['who', 'what', 'when', 'where', 'why']
#Humor
genre_word_usage('humor', w_words)
print(' ') #Print a line in between
#News
genre_word_usage('news', w_words)
who: 49 what: 46 when: 62 where: 16 why: 13
who: 268 what: 95 when: 169 where: 59 why: 14
It looks like humor asks “Why?” more than the news does. Interesting
#Let's make a table of different modals in different genres
cfd = nltk.ConditionalFreqDist((genre, word)
for genre in brown.categories()
for word in brown.words(categories=genre))
genres = ['news', 'religion', 'hobbies', 'science_fiction', 'romance', 'humor']
modals = ['can', 'could', 'may', 'might', 'must', 'will']
cfd.tabulate(conditions=genres, samples=modals)
can could may might must will
news 93 86 66 38 50 389
religion 82 59 78 12 54 71
hobbies 268 58 131 22 83 264
science_fiction 16 49 4 12 8 16
romance 74 193 11 51 45 43
humor 16 30 8 8 9 13
#Now let's look at inaugural addresses
from nltk.corpus import inaugural
print(inaugural.fileids())
print([fileid[:4] for fileid in inaugural.fileids()])
['1789-Washington.txt', '1793-Washington.txt', '1797-Adams.txt', '1801-Jefferson.txt', '1805-Jefferson.txt', '1809-Madison.txt', '1813-Madison.txt', '1817-Monroe.txt', '1821-Monroe.txt', '1825-Adams.txt', '1829-Jackson.txt', '1833-Jackson.txt', '1837-VanBuren.txt', '1841-Harrison.txt', '1845-Polk.txt', '1849-Taylor.txt', '1853-Pierce.txt', '1857-Buchanan.txt', '1861-Lincoln.txt', '1865-Lincoln.txt', '1869-Grant.txt', '1873-Grant.txt', '1877-Hayes.txt', '1881-Garfield.txt', '1885-Cleveland.txt', '1889-Harrison.txt', '1893-Cleveland.txt', '1897-McKinley.txt', '1901-McKinley.txt', '1905-Roosevelt.txt', '1909-Taft.txt', '1913-Wilson.txt', '1917-Wilson.txt', '1921-Harding.txt', '1925-Coolidge.txt', '1929-Hoover.txt', '1933-Roosevelt.txt', '1937-Roosevelt.txt', '1941-Roosevelt.txt', '1945-Roosevelt.txt', '1949-Truman.txt', '1953-Eisenhower.txt', '1957-Eisenhower.txt', '1961-Kennedy.txt', '1965-Johnson.txt', '1969-Nixon.txt', '1973-Nixon.txt', '1977-Carter.txt', '1981-Reagan.txt', '1985-Reagan.txt', '1989-Bush.txt', '1993-Clinton.txt', '1997-Clinton.txt', '2001-Bush.txt', '2005-Bush.txt', '2009-Obama.txt']
['1789', '1793', '1797', '1801', '1805', '1809', '1813', '1817', '1821', '1825', '1829', '1833', '1837', '1841', '1845', '1849', '1853', '1857', '1861', '1865', '1869', '1873', '1877', '1881', '1885', '1889', '1893', '1897', '1901', '1905', '1909', '1913', '1917', '1921', '1925', '1929', '1933', '1937', '1941', '1945', '1949', '1953', '1957', '1961', '1965', '1969', '1973', '1977', '1981', '1985', '1989', '1993', '1997', '2001', '2005', '2009']
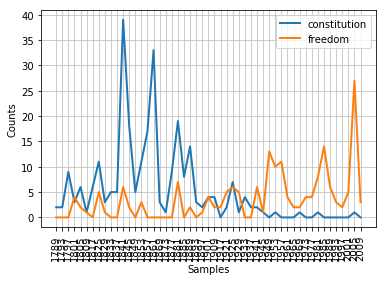
#We can even look at how words were used over time
cfd = nltk.ConditionalFreqDist(
(target, fileid[:4])
for fileid in inaugural.fileids()
for w in inaugural.words(fileid)
for target in ['freedom', 'constitution']
if w.lower().startswith(target))
cfd.plot()
genre_word = [(genre, word)
for genre in ['news', 'humor']
for word in brown.words(categories=genre)]
cfd = nltk.ConditionalFreqDist(genre_word)
cfd.conditions()
print(cfd['humor'].most_common(20))
print(cfd['news'].most_common(20))
[(',', 1331), ('the', 930), ('.', 877), ('of', 515), ('and', 512), ('a', 505), ('to', 463), ('``', 343), ("''", 340), ('in', 334), ('was', 274), ('that', 241), ('I', 239), ('it', 162), ('?', 152), ('for', 150), ('had', 149), ('he', 146), ('his', 137), ('you', 131)]
[('the', 5580), (',', 5188), ('.', 4030), ('of', 2849), ('and', 2146), ('to', 2116), ('a', 1993), ('in', 1893), ('for', 943), ('The', 806), ('that', 802), ('``', 732), ('is', 732), ('was', 717), ("''", 702), ('on', 657), ('at', 598), ('with', 545), ('be', 526), ('by', 497)]
#Here's a function to calculate lexical diversity. We may use it at some point, so I'll just put it here
def lexical_diversity(my_text_data):
word_count = len(my_text_data)
vocab_size = len(set(my_text_data))
diversity_score = vocab_size / word_count
return diversity_score
#And here's a quick version of a function that converts to plural
def plural(word):
if word.endswith('y'):
return word[:-1] + 'ies'
elif word[-1] in 'sx' or word[-2:] in ['sh', 'ch']:
return word + 'es'
elif word.endswith('an'):
return word[:-2] + 'en'
else:
return word + 's'
#Let's make a function to find rare or unusual (or mispelled) words
def unusual_words(text):
text_vocab = set(w.lower() for w in text if w.isalpha())
english_vocab = set(w.lower() for w in nltk.corpus.words.words())
unusual = text_vocab - english_vocab
return sorted(unusual)
text = "I ain't got no better idizzle that to take the twizzle to fizzle, you know?"
text = nltk.word_tokenize(text)
unusual_words(text)
['idizzle']
Apparently, twizzle and fizzle are not unusual words
#we sometimes want to filter out of a document before further processing.
#Stopwords usually have little lexical content, and their presence in a text fails to distinguish it from other texts.
from nltk.corpus import stopwords
stopwords.words('english')
['i',
'me',
'my',
'myself',
'we',
'our',
'ours',
'ourselves',
'you',
'your',
'yours',
'yourself',
'yourselves',
'he',
'him',
'his',
'himself',
'she',
'her',
'hers',
'herself',
'it',
'its',
'itself',
'they',
'them',
'their',
'theirs',
'themselves',
'what',
'which',
'who',
'whom',
'this',
'that',
'these',
'those',
'am',
'is',
'are',
'was',
'were',
'be',
'been',
'being',
'have',
'has',
'had',
'having',
'do',
'does',
'did',
'doing',
'a',
'an',
'the',
'and',
'but',
'if',
'or',
'because',
'as',
'until',
'while',
'of',
'at',
'by',
'for',
'with',
'about',
'against',
'between',
'into',
'through',
'during',
'before',
'after',
'above',
'below',
'to',
'from',
'up',
'down',
'in',
'out',
'on',
'off',
'over',
'under',
'again',
'further',
'then',
'once',
'here',
'there',
'when',
'where',
'why',
'how',
'all',
'any',
'both',
'each',
'few',
'more',
'most',
'other',
'some',
'such',
'no',
'nor',
'not',
'only',
'own',
'same',
'so',
'than',
'too',
'very',
's',
't',
'can',
'will',
'just',
'don',
'should',
'now',
'd',
'll',
'm',
'o',
're',
've',
'y',
'ain',
'aren',
'couldn',
'didn',
'doesn',
'hadn',
'hasn',
'haven',
'isn',
'ma',
'mightn',
'mustn',
'needn',
'shan',
'shouldn',
'wasn',
'weren',
'won',
'wouldn']
#Are too many words in your writing stop words? Or perhaps not enough?
def content_fraction(text):
stopwords = nltk.corpus.stopwords.words('english')
content = [w for w in text if w.lower() not in stopwords]
return len(content) / len(text)
content_fraction(nltk.corpus.reuters.words())
0.735240435097661
Wordnet is one of the most important tools. Let’s look at how to use it
#We can use wordnet to find synonyms:
from nltk.corpus import wordnet as wn
wn.synsets('book')
[Synset('book.n.01'),
Synset('book.n.02'),
Synset('record.n.05'),
Synset('script.n.01'),
Synset('ledger.n.01'),
Synset('book.n.06'),
Synset('book.n.07'),
Synset('koran.n.01'),
Synset('bible.n.01'),
Synset('book.n.10'),
Synset('book.n.11'),
Synset('book.v.01'),
Synset('reserve.v.04'),
Synset('book.v.03'),
Synset('book.v.04')]
#Book has lots of synsets. Let's choose one and see what synonyms we can find
wn.synset('book.n.02').lemma_names()
#Let's also look at what the definition is, and find an example
print(wn.synset('book.n.02').definition())
print(wn.synset('book.n.02').examples())
physical objects consisting of a number of pages bound together
['he used a large book as a doorstop']
#Clearly, book has lots of definitions. Let's look at all the lemmas here:
wn.lemmas('book')
[Lemma('book.n.01.book'),
Lemma('book.n.02.book'),
Lemma('record.n.05.book'),
Lemma('script.n.01.book'),
Lemma('ledger.n.01.book'),
Lemma('book.n.06.book'),
Lemma('book.n.07.book'),
Lemma('koran.n.01.Book'),
Lemma('bible.n.01.Book'),
Lemma('book.n.10.book'),
Lemma('book.n.11.book'),
Lemma('book.v.01.book'),
Lemma('reserve.v.04.book'),
Lemma('book.v.03.book'),
Lemma('book.v.04.book')]
Chapter 3
from nltk import word_tokenize
Working with raw text
# Let's start by grabbing a new book from project Gutenberg. We'll grab one from the web that isn't in the nltk corpus
# Note that this will give you an error if you're using a VPN
from urllib import request
url = "http://www.gutenberg.org/files/2554/2554-0.txt"
response = request.urlopen(url)
raw = response.read().decode('utf8')
print(raw[:75])
The Project Gutenberg EBook of Crime and Punishment, by Fyodor Dostoevsky
#The first step is to tokenize the text
tokens = word_tokenize(raw)
Regular expressions
import re
wordlist = [w for w in nltk.corpus.words.words('en') if w.islower()]
#wordlist is a list of all words in English
wordlist[:50]
['a',
'aa',
'aal',
'aalii',
'aam',
'aardvark',
'aardwolf',
'aba',
'abac',
'abaca',
'abacate',
'abacay',
'abacinate',
'abacination',
'abaciscus',
'abacist',
'aback',
'abactinal',
'abactinally',
'abaction',
'abactor',
'abaculus',
'abacus',
'abaff',
'abaft',
'abaisance',
'abaiser',
'abaissed',
'abalienate',
'abalienation',
'abalone',
'abampere',
'abandon',
'abandonable',
'abandoned',
'abandonedly',
'abandonee',
'abandoner',
'abandonment',
'abaptiston',
'abarthrosis',
'abarticular',
'abarticulation',
'abas',
'abase',
'abased',
'abasedly',
'abasedness',
'abasement',
'abaser']
#Let's search for all words that end in 'ed'. We use the dollar sign to specify that we're looking at the end of the word
ed_words = [w for w in wordlist if re.search('ed$', w)]
print(len(ed_words))
9148
#Also good for crossword puzzles
[w for w in wordlist if re.search('^..j..t..$', w)]
['abjectly',
'adjuster',
'dejected',
'dejectly',
'injector',
'majestic',
'objectee',
'objector',
'rejecter',
'rejector',
'unjilted',
'unjolted',
'unjustly']
# the ? symbol specifies that the previous character is optional. Thus «^e-?mail$» will match both email and e-mail.
Cleaning text
raw = """DENNIS: Listen, strange women lying in ponds distributing swords
... is no basis for a system of government. Supreme executive power derives from
... a mandate from the masses, not from some farcical aquatic ceremony."""
tokens = word_tokenize(raw)
#Stemmers
#You can use a stemmer to sort through other forms of the word
class IndexedText(object):
def __init__(self, stemmer, text):
self._text = text
self._stemmer = stemmer
self._index = nltk.Index((self._stem(word), i)
for (i, word) in enumerate(text))
def concordance(self, word, width=40):
key = self._stem(word)
wc = int(width/4) # words of context
for i in self._index[key]:
lcontext = ' '.join(self._text[i-wc:i])
rcontext = ' '.join(self._text[i:i+wc])
ldisplay = '{:>{width}}'.format(lcontext[-width:], width=width)
rdisplay = '{:{width}}'.format(rcontext[:width], width=width)
print(ldisplay, rdisplay)
def _stem(self, word):
return self._stemmer.stem(word).lower()
porter = nltk.PorterStemmer()
grail = nltk.corpus.webtext.words('grail.txt')
text = IndexedText(porter, grail)
text.concordance('lie')
r king ! DENNIS : Listen , strange women lying in ponds distributing swords is no
beat a very brave retreat . ROBIN : All lies ! MINSTREL : [ singing ] Bravest of
Nay . Nay . Come . Come . You may lie here . Oh , but you are wounded !
doctors immediately ! No , no , please ! Lie down . [ clap clap ] PIGLET : Well
ere is much danger , for beyond the cave lies the Gorge of Eternal Peril , which
you . Oh ... TIM : To the north there lies a cave -- the cave of Caerbannog --
h it and lived ! Bones of full fifty men lie strewn about its lair . So , brave k
not stop our fight ' til each one of you lies dead , and the Holy Grail returns t
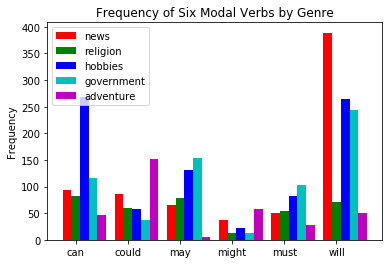
#Let's make a function for plotting words by how commonly they're used in each genre
from numpy import arange
from matplotlib import pyplot
colors = 'rgbcmyk' # red, green, blue, cyan, magenta, yellow, black
def bar_chart(categories, words, counts):
"Plot a bar chart showing counts for each word by category"
ind = arange(len(words))
width = 1 / (len(categories) + 1)
bar_groups = []
for c in range(len(categories)):
bars = pyplot.bar(ind+c*width, counts[categories[c]], width,
color=colors[c % len(colors)])
bar_groups.append(bars)
pyplot.xticks(ind+width, words)
pyplot.legend([b[0] for b in bar_groups], categories, loc='upper left')
pyplot.ylabel('Frequency')
pyplot.title('Frequency of Six Modal Verbs by Genre')
pyplot.show()
genres = ['news', 'religion', 'hobbies', 'government', 'adventure']
modals = ['can', 'could', 'may', 'might', 'must', 'will']
cfdist = nltk.ConditionalFreqDist(
(genre, word)
for genre in genres
for word in nltk.corpus.brown.words(categories=genre)
if word in modals)
counts = {}
for genre in genres:
counts[genre] = [cfdist[genre][word] for word in modals]
bar_chart(genres, modals, counts)
Content-Type: text/html
<html><body>
<img src="modals.png"/>
</body></html>
C:\Users\HMISYS\Anaconda3\lib\site-packages\matplotlib\__init__.py:1405: UserWarning:
This call to matplotlib.use() has no effect because the backend has already
been chosen; matplotlib.use() must be called *before* pylab, matplotlib.pyplot,
or matplotlib.backends is imported for the first time.
warnings.warn(_use_error_msg)
Chapter 5
#First tokenize
text = word_tokenize("They refuse to permit us to obtain the refuse permit")
#Then tag
nltk.pos_tag(text)
#Note that this sentence has the homonym 'permit', yet it is tagged correctly
[('They', 'PRP'),
('refuse', 'VBP'),
('to', 'TO'),
('permit', 'VB'),
('us', 'PRP'),
('to', 'TO'),
('obtain', 'VB'),
('the', 'DT'),
('refuse', 'NN'),
('permit', 'NN')]
#By convention in NLTK, a tagged token is represented using a tuple consisting of the token and the tag
tagged_token = nltk.tag.str2tuple('fly/NN')
tagged_token
('fly', 'NN')
#I don't know why this box isn't working
my_text='''this is my test test for auto tagging strings'''
[nltk.tag.str2tuple(t) for t in my_text.split()]
[('this', None),
('is', None),
('my', None),
('test', None),
('test', None),
('for', None),
('auto', None),
('tagging', None),
('strings', None)]
#Let's see what tags are most common
from nltk.corpus import brown
brown_news_tagged = brown.tagged_words(categories='news', tagset='universal')
tag_fd = nltk.FreqDist(tag for (word, tag) in brown_news_tagged)
tag_fd.most_common()
[('NOUN', 30654),
('VERB', 14399),
('ADP', 12355),
('.', 11928),
('DET', 11389),
('ADJ', 6706),
('ADV', 3349),
('CONJ', 2717),
('PRON', 2535),
('PRT', 2264),
('NUM', 2166),
('X', 92)]
#What are the most common verbs?
wsj = nltk.corpus.treebank.tagged_words(tagset='universal')
word_tag_fd = nltk.FreqDist(wsj)
[wt[0] for (wt, _) in word_tag_fd.most_common() if wt[1] == 'VERB'][:50]
['is',
'said',
'was',
'are',
'be',
'has',
'have',
'will',
'says',
'would',
'were',
'had',
'been',
'could',
"'s",
'can',
'do',
'say',
'make',
'may',
'did',
'rose',
'made',
'does',
'expected',
'buy',
'take',
'get',
'might',
'sell',
'added',
'sold',
'help',
'including',
'should',
'reported',
'according',
'pay',
'compared',
'being',
'fell',
'began',
'based',
'used',
'closed',
"'re",
'want',
'see',
'took',
'yield']
#What words occur after the word "often"?
brown_learned_text = brown.words(categories='learned')
sorted(set(b for (a, b) in nltk.bigrams(brown_learned_text) if a == 'often'))
[',',
'.',
'accomplished',
'analytically',
'appear',
'apt',
'associated',
'assuming',
'became',
'become',
'been',
'began',
'call',
'called',
'carefully',
'chose',
'classified',
'colorful',
'composed',
'contain',
'differed',
'difficult',
'encountered',
'enough',
'equate',
'extremely',
'found',
'happens',
'have',
'ignored',
'in',
'involved',
'more',
'needed',
'nightly',
'observed',
'of',
'on',
'out',
'quite',
'represent',
'responsible',
'revamped',
'seclude',
'set',
'shortened',
'sing',
'sounded',
'stated',
'still',
'sung',
'supported',
'than',
'to',
'when',
'work']
Chapter 6
#Let's practice classifying a document. We had plenty of labeled corpora to work with
#We'll start with movie reviews. They are either positive or negative
import random
from nltk.corpus import movie_reviews
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
#Next, we define a feature extractor for documents, so the classifier will know which aspects of the data it should pay attention to
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
word_features = list(all_words)[:2000] #Restrict to 2000 most common words
def document_features(document): #Check if the word is there
document_words = set(document) #This is actually faster than checking if a word is in a list
features = {}
for word in word_features:
features['contains({})'.format(word)] = (word in document_words)
return features
# You can also print with the statement below
#print(document_features(movie_reviews.words('pos/cv957_8737.txt')))
#Let's see how good the classifier is
featuresets = [(document_features(d), c) for (d,c) in documents]
train_set, test_set = featuresets[100:], featuresets[:100]
classifier = nltk.NaiveBayesClassifier.train(train_set)
#Print the results
print(nltk.classify.accuracy(classifier, test_set))
0.82
#Now look at what words were most important
classifier.show_most_informative_features(5)
Most Informative Features
contains(unimaginative) = True neg : pos = 7.7 : 1.0
contains(suvari) = True neg : pos = 7.0 : 1.0
contains(mena) = True neg : pos = 7.0 : 1.0
contains(schumacher) = True neg : pos = 7.0 : 1.0
contains(atrocious) = True neg : pos = 6.6 : 1.0
#Anger surprises me for a positive review. And I wonder what "topping" is all about.
Chapter 7
#Here are the three basic steps to preprocessing data
def ie_preprocess(document):
sentences = nltk.sent_tokenize(document)
sentences = [nltk.word_tokenize(sent) for sent in sentences]
sentences = [nltk.pos_tag(sent) for sent in sentences]
sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"),
... ("dog", "NN"), ("barked", "VBD"), ("at", "IN"), ("the", "DT"), ("cat", "NN")]
grammar = "NP: {<DT>?<JJ>*<NN>}"
cp = nltk.RegexpParser(grammar)
result = cp.parse(sentence)
print(result)
(S
(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBD
at/IN
(NP the/DT cat/NN))
result.draw()
Other
Pronounciation
# We'll use this corpus to find how words are pronounced
from nltk.corpus import cmudict
prondict = cmudict.dict()
# Prondict is not a function, but a huge dictionary. So it is not called like prondict('word'), but instead referenced
# like prondict['word']
prondict['minute']
[['M', 'IH1', 'N', 'AH0', 'T'],
['M', 'AY0', 'N', 'UW1', 'T'],
['M', 'AY0', 'N', 'Y', 'UW1', 'T']]